Fouten bij hypothesetoetsen
Op basis van een hypothesetoets die we uitvoeren op basis van verzamelde data uit een steekproef van een bepaalde populatie proberen we een besluit te vormen over de hypothese binnen de populatie. Aangezien een steekproef en metingen gepaard gaan met variabiliteit en onzekerheid, kunnen er fouten optreden. In onderstaande tabel vinden jullie een grafische weergave van deze mogelijke fouten:
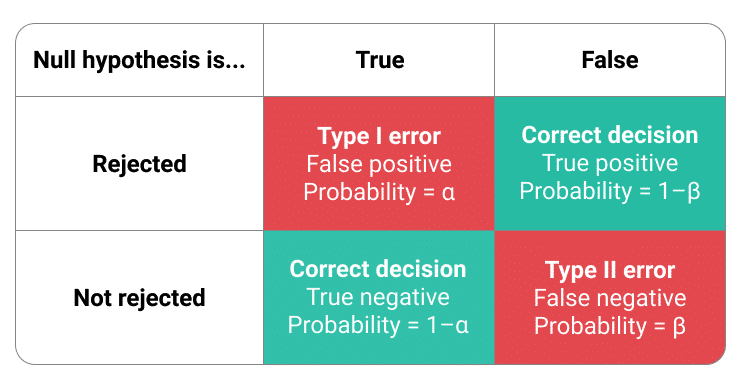
Figure 1.1: Visuele samenvatting van fouten bij hypothesetoetsen.
Voorbeeld: Veronderstel dat er binnen de populatie van kinesitherapeuten geen verschil is in het aantal uren die gepresteerd worden tussen mannen en vrouwen. We organiseren binnen deze populatie (\(n = 30\)) en evaluaeren het aantal uren. Uiteindelijk voeren we een statistische toets uit, waaruit we finaal besluiten of er al dan geen verschil is in gepresteerde uren. Hiervoor veronderstellen we volgende hypothesen:
- \(H_0\): Er is geen verschil in gepresteerde uren tussen mannen en vrouwen.
- \(H_1\): Er is een verschil in gepresteerde uren tussen mannen en vrouwen.
Indien we binnen de populatie weten dat er geen verschil is (\(H_0\) is dus juist), zijn er twee mogelijke uitkomsten:
- We verwerpen \(H_0\) en besluiten dus dat er wel een verschil is. In dit scenario maken we een fout en binnen de inductieve statistiek wordt deze fout aangeduid als \(\alpha\) (Type I error). Algemeen wordt aanvaard om deze \(\alpha\) op 5% te zetten.
- We aanvaarden \(H_0\) en besluiten dus dat er wel een verschil is. In dit scenario maken we een correcte beslissing.
Indien we binnen de populatie weten dat er wel verschil is (\(H_0\) is dus fout), zijn er twee mogelijke uitkomsten:
- We verwerpen \(H_0\) en besluiten dus dat er wel een verschil is. In dit scenario maken we een correcte beslissing.
- We aanvaarden \(H_0\) en besluiten dus dat er geen verschil is. In dit scenario maken we een fout en binnen de inductieve statistiek wordt deze fout aangeduid als \(\beta\) (Type II error). Over de grootte van \(\beta\) is er minder consensus, maar 80% wordt vaak algemeen aanvaard.
In bovenstaande figuur 1.1 kan je de vier verschillende scenario’s zoals hierboven beschreven herkennen.